


Chief economic advisor Krishnamurthy Subramanian during a press conference on the 2021 Economic Survey in New Delhi, January 2021. Photo: PTI.
Chapter 1 of the 2021 Economic Survey is grandly entitled “Saving Lives and Livelihoods Amidst a Once-in-a-Century Crisis”. It claims to tell the story of India’s COVID-19 crisis and the government’s response.
This report is important, being the official narrative of the Indian epidemic, and ambitious in its discussions of historical and international data. It includes several little primers on epidemiology and surrounds data analysis with scientific and philosophical discussion, including quotes from the Mahabharata.
Look closer, though, and we find that it gives little insight into India’s COVID-19 crisis itself. It does, however, tell us how the Centre would like people to view its response. In a line:
“The analysis shows that India has been able to effectively manage both the spread of COVID-19 and the fatalities.”
Or, in more flowery prose:
“The clear objective of ‘Jaan Hai to Jahan hai’ and to ‘break the chain of spread’ before it reaches ‘community transmission’ helped the government face the dilemma of ‘lives vs livelihood’, pace the sequence of policy interventions and adapt its response as per the evolving situation.”
States are repeatedly singled out for praise or censure. For example:
“Uttar Pradesh, Gujarat and Bihar have restricted the case spread the best; Kerala, Telangana and Andhra Pradesh have saved the most lives; Maharashtra has under-performed the most in restricting the spread of cases and in saving lives.”
Such bold claims are made throughout the report. Let’s first look at some of these.
Do the report’s claims pass common-sense tests?
Even without much technical analysis, we get hints that something is very wrong. The report draws heavily on international data and reaches some surprising conclusions.
Consider figure 12 in the document. How can India and the US, both estimated from seroprevalence data to have had similar levels of infection, appear at the top and bottom of the rankings for limiting the spread of COVID-19?
In the same figure, the UK is shown as one of the most successful countries in restricting the spread of COVID-19. Can this really be the case despite the UK having among the highest recorded COVID-19 mortality rates in the world?
And – perhaps just a glitch – why is Brazil absent from this figure?

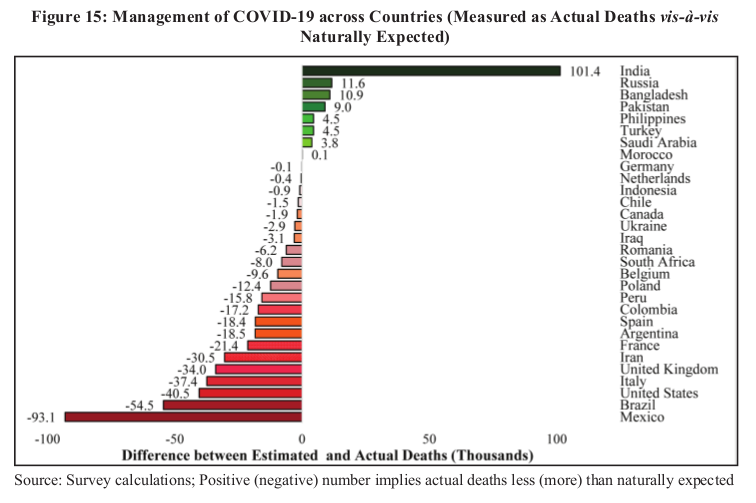
In another figure, no. 15, Russia is ranked second only to India for its success in reducing COVID-19 mortality. But it was recently confirmed by Rosstat, the Russian statistics agency, that most Russian COVID-19 deaths have not entered its official tally. This policy was openly acknowledged, and reported on as early as May 2020.
{kind=link}
Similar stories are repeated at the level of states. Kerala has apparently done badly, according to figure 18, at restricting disease spread even though seroprevalence data indicates that it has, so far, seen considerably lower levels of infection than the national average. Telangana is cited in figure 19 as a state that has been highly successful in reducing mortality. But there have been numerous reports on Telangana’s systematic undercounting of COVID-19 deaths.
{kind=link}
{kind=link}
In figure 10, Bihar appears as a state that successfully controlled COVID-19 via “ramped up testing” – but there is evidence of large-scale manipulation of testing data in Bihar. This had been discussed in previous reports, and seroprevalence data indicates that only a tiny fraction of Bihar’s infections were captured as cases. In fact, Bihar is heaped with praise for having kept case numbers low, even as infections soared.
{kind=link}
Such examples – and there are many more – indicate that the context and integrity of the data is never considered. But they also raise the question of how exactly the authors have used the data.
What data did the survey use? And how?
The report bases its conclusions mainly on recorded COVID-19 cases and deaths. These are taken at face value, while seroprevalence data and data around disease surveillance are ignored.
Case and fatality data from “the top 30 countries in terms of total confirmed cases” are used to predict how many cases and deaths to expect in different countries and different Indian states. Fewer cases or deaths than “naturally expected” is equated to success.
Expected cases are assumed to depend on a variety of factors such as population density, the fraction over 60 years old, and levels of testing. The dependence follows a so-called power law. Expected COVID-19 deaths are calculated similarly.
There are huge question marks over this whole process. Why have some factors, like urbanisation, been ignored even when Indian data indicates that it is strongly associated with case and death numbers? Why has international data on how age affects COVID-19 fatality rates been ignored when calculating expected fatalities? And why use power laws?
Leaving aside such concerns, there are two questions we can pose about the report’s “laws” to predict cases and deaths.
1. How well do they explain the international data used to construct them? We have no idea. In a 42-page document, there are no hints about how much each factor explains variations in case or death levels. This would normally be a very standard part of such analysis.
2. Are they scientifically correct – i.e. do they tally with conclusions from other approaches? The answer seems to be ‘no’. The report’s conclusions repeatedly clash with evidence. Some examples have been given earlier.
We thus have laws whose derivation is questionable, and which don’t seem to “work” very well to explain either international or Indian data. On top of this, the results are presented in deceptive ways.
Misleading plots and figures
The report ranks countries or states according to their success in reducing COVID-19 cases or deaths. We have seen that the underlying calculations are spurious. But the rankings are even more misleading because cases and deaths are not given per capita. This magnifies the implied success or failure of large countries or states.
For example, if we took population into account, then Russia, the UK and Saudi Arabia would “outperform” India at reducing cases in figure 12. The optics of this figure would change dramatically.
Figure 18 suggests that Bihar has outperformed Delhi at reducing cases – but if we were to factor in Bihar’s much larger population, the rankings would be reversed.
The document has a number of plots based on linear regression, a technique to establish relationships between different quantities. But crucial information is always missing, making these plots deceptive.
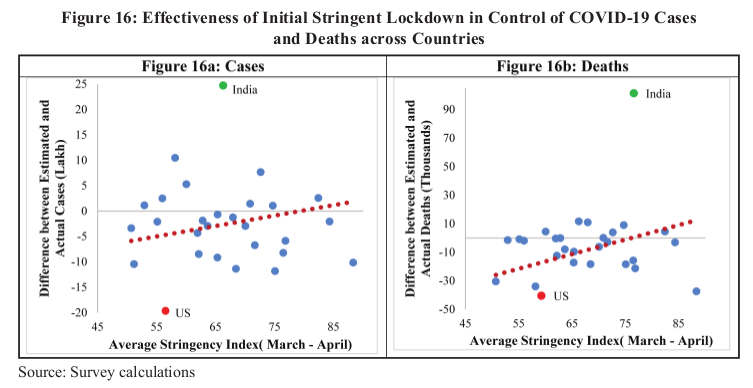
Figure 16 is an example. It is used to argue that lockdowns helped countries control cases and deaths. The claim is probably true – but does the figure demonstrate it? Not clearly. The correlations appear weak and calculations of their significance are missing. Moreover, the data on cases does not appear to match that in figure 12 and, as usual, population has not been factored in.
Is Indian data explained by successful policies?
Figure 16 is intended to clinch the argument that “the intense lockdown helped India to effectively manage the pandemic”. But it actually tells us something quite different. India is a massive outlier in the plots in this figure. If indeed there is a pattern, then Indian data breaks this pattern.
The authors even mention this fact, but appear to ignore its meaning. It suggests that their model of “expected” cases and deaths is not relevant to Indian data and/or India’s fewer-than-expected cases and deaths are not a result of successful mitigation.
Just to be clear, this is not an argument about the lockdown itself. The lockdown probably slowed the spread of disease, although poor planning and little support for those it left vulnerable led to extreme side-effects, particularly the migrant crisis. The lockdown may also have locally accelerated spread, for example by preventing decongestion in urban slums. Its full effects require more and careful study.
The point is that the report’s flawed data analysis undermines its key claim that India has effectively managed COVID-19 spread and fatalities.
In practice, India’s response to COVID-19 has included a huge number of local interventions that have helped to slow spread. This is true across the country, including in badly hit Maharashtra. The Economic Survey does no justice to these efforts, and instead rewards data fudging and punishes transparency.
Also read: The Sensible, the Debatable and the Bizarre in the CEA’s Defence of India’s Lockdown
Conclusions
India’s case and fatality data can be explained by a combination of factors, including:
- Mitigation slowing the spread of disease
- Factors such as poor housing and population density accelerating the spread of disease
- Age structure reducing severe disease and mortality, and
- Highly variable – and generally weak – surveillance of both disease and deaths
There is evidence for all of these playing important parts in explaining national and regional data. With cases on the rise again, it is important to disentangle these factors. We need to understand if rural districts that have so far registered few COVID-19 cases have been spared or poorly surveilled. And in either case, why? But a lack of data often makes answering such questions hard.
The authors of the Economic Survey missed an opportunity to examine this complex story scientifically. They could have used all the data available and suggested ways to fill the gaps. They chose instead to construct dubious laws for how many cases or deaths to expect in a given region, using unreliable data and questionable assumptions. They rushed to interpret deviations from their predictions as success or failure – even though the laws seem to be at odds with Indian data.
Ultimately, the report is not just scientifically weak – it misinterprets the data used and consistently ignores inconvenient data and information. It sets up a framework that is of no use to understand the epidemic so far. It will be of little help in managing whatever comes next.
Murad Banaji is a mathematician with an interest in disease modelling.