


A healthcare worker checks the temperature of a resident during a medical campaign for COVID-19 at a slum area in Mumbai, July 1, 2020. Photo: Reuters/Francis Mascarenhas/Files.
The results of two recent seroprevalence surveys in Delhi and Mumbai provide intriguing insights into COVID-19 in India. Both surveys measured how many people had developed immunoglobulin G (IgG) antibodies to the novel coronavirus.
First, a note of caution. The data available is incomplete, and the surveys may have over- or under-estimated disease prevalence for various reasons. There may be errors in the tests’ properties, or the sampled populations may not be representative of the cities. For example, in Mumbai, only 6,936 people were tested, all from just three wards. There was some non-cooperation in non-slum areas that could have skewed the results as well.
Limitations aside, the data suggests two things: that the virus has spread wide and that the fatalities have been relatively low.
What exactly did the surveys find?
The headline figures reported thus far are as follows. In Delhi, by early July, 23% of those surveyed had developed IgG antibodies. In Mumbai, by around the same time, 57% of those surveyed in slums and 16% in non-slum areas had developed these antibodies. Assuming that about 40% of Mumbai’s population resides in slums, this would imply a city-wide seroprevalence of roughly 33% by the time of the survey.
For some international context, London and New York city reported estimated seroprevalences of 17.5% and 23% respectively in late April, when the epidemics in these two cities were winding down. These numbers will have grown subsequently, but not dramatically. On the other hand, while the epidemics in Mumbai and Delhi are slowing, there is still some way to go, and seroprevalence will continue to rise for some time. In this sense, Mumbai and Delhi have been harder hit.
Fatality rates
But when it comes to COVID-19 deaths, it appears Delhi and Mumbai have not been hit so hard. What we would like to gauge is the proportion of people with COVID-19 who will die, called the disease’ infection fatality rate (IFR). A value of 0.1% would amount to about 1 in every 1,000 people with COVID-19 dying. Let’s consider two comparisons.
1. Delhi and New York city – Both cities recorded about 23% seroprevalence, amounting to about 1.9 million infections in NYC and about 4.4 million in Delhi. The stark difference is that NYC data indicates about 15,000 fatalities shortly after its survey, while Delhi had recorded only about 3,200 fatalities shortly after its survey. At face value, COVID-19 appears to have been ten-times deadlier in NYC than in Delhi.
2. London and Mumbai – Both cities recorded about 5,500 COVID-19 deaths shortly after their serosurveys. The difference, this time, is that London’s deaths occurred among an estimated 1.6 million infected people while Mumbai’s were among an estimated 4.5 million infected people. At face value, COVID-19 appears to have been three-times deadlier in London than in Mumbai.
A standard approach to calculating IFR assumes some typical delays between infection and a positive antibody test, and infection and death. A summary of approximate values from this approach for our four cities is given in the table below.
When it comes to claims about fatality, there are several things we should bear in mind. First, we do expect variation. Fatality rates for COVID-19 depend heavily on age, underlying health conditions (comorbidities) and possibly prior immunity. India’s young population would partly explain the lower estimated IFR values in India. However, crucially, we should consider possible fatality undercounting as well – and in all regions.
Mumbai and Delhi are among several cities and states in India that have had a large number of deaths due to COVID-19 omitted from official statistics, sometimes followed by data “reconciliations”. In Mumbai, for example, scouring Mumbai’s COVID-19 bulletins shows that about 1,700 old COVID-19 fatalities had been added to the official count in June. Something similar occurred in Delhi, although only some of Delhi’s COVID-19 bulletins indicated which fatalities being added were current and which were old.
Given the numerous episodes of fatality undercounting in India, many on a large scale, simple-minded estimates of IFR that ignore missing deaths seems naïve at best, and dishonest at worst. Instead, we should estimate IFR under different assumptions about missing fatalities, and expect that time and/or further data will eventually provide more clarity.
Modelling approaches
One approach involves simulating epidemics while making different assumptions about IFR. This yields some plausible scenarios for the evolution of an epidemic that can be cross-checked against both COVID-19 data and news reports.
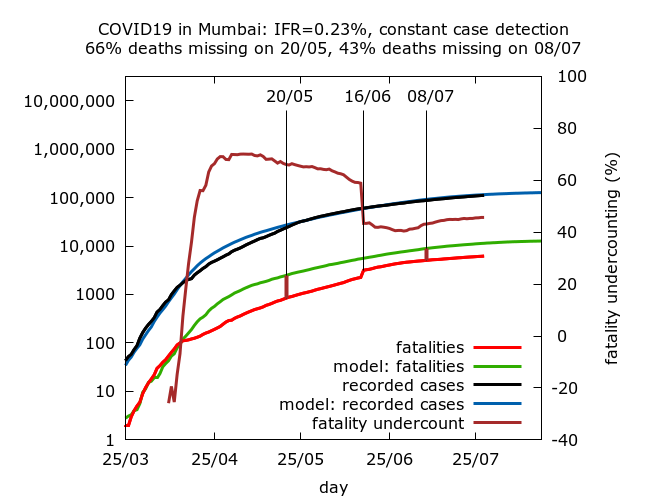
For example, a scenario consistent with Mumbai’s data is as follows. The headline is that Mumbai’s seroprevalence, case and fatality data taken together are consistent with an IFR of 0.23% and about 40% fatalities missing in early July. However, the simulation additionally tells us that COVID-19 deaths start to go missing in mid-April. Apparent fatality undercounting peaks at about 70% by early May. There is then gradual improvement until a major reconciliation on June 16, after which fatality undercounting hovers around 40%. The reconciliation remains incomplete.
A scenario consistent with the seroprevalence estimate for Delhi is pictured next. The headline this time is that Delhi’s seroprevalence, case and fatality data are consistent with an IFR of 0.14% and about 40% of fatalities missing in early July. But again, the simulation gives us a story to accompany the headline. As in Mumbai, deaths start to go missing in mid-April, with apparent fatality undercounting peaking at about 82% by early May. There is then a steady reconciliation, followed by a major one on June 16, bringing the fatality undercounting to below 40%. After this – in this simulation – the fatality undercounting begins rising again.

Other simulations and the technical material on which this analysis is based are available here for Delhi and here for Mumbai. They suggest plausible IFR estimates of between 0.09% and 0.45%. The estimates for Delhi are somewhat lower than those for Mumbai.
Of course, model-based estimates are just that. But unlike crude calculations, the stories they tell can be cross-checked against other evidence, and often suggest questions to investigate. For example, a question that has received nowhere near enough attention is why there was a precipitous fall in the ratio of recorded deaths to expected deaths in Mumbai in mid-April. This fall is not explained by other available data.
Also read: Tests Used by BMC in Mumbai Had Many False Negatives. Don’t Be Surprised.
The seroprevalence data from Delhi and Mumbai provides valuable pieces in an emerging jigsaw puzzle – but needs to be interpreted with care. It indicates rapid spread of COVID-19 in cities, particularly in areas with poor housing, and casts doubts on feel-good stories about the successful control of COVID-19 in urban slums.
Taken alongside plausible levels of fatality undercounting, the data gives us a range of possible IFR values, and pinpointing a single value is misleading at this stage. There is still much to understand.
Murad Banaji is a mathematician with an interest in disease modelling.